Apache Calcite:一款开源 SQL 解析工具
Apache Calcite 是什么?
Apache Calcite™ is a dynamic data management framework.

基本概念
Catelog
用于定义 SQL 语义相关的元数据与命名空间
SQL Parser
负责将 SQL 转化成 AST(Abstract Syntax Tree)
SQL Validator
负责通过 Catalog 对 AST 进行校证
Query Optimizer
负责将 AST 转化成物理执行计划、优化物理执行计划
SQL Generator
负责将物理执行计划反向转化成 SQL 语句
特性
- 支持标准 SQL 语言
- 通过适配器(Adapter)可以支持连接任何数据源
- 支持丰富的关系代数(并集、交集、连接、笛卡尔积等)
- 支持对逻辑规划规则进行定制(例如 Filter 下推)
- 支持成本模型优化(CBO, Cost-Based Optimizer 和 RBO, Rule-Based Optimizer)
- 支持管理物化视图(Materialized view)
- 支持查询流式数据
- 稳定可靠(开发迭代 10 年以上)
- 已贡献给 Apache 基金会(于 2013 年)
- 开源社区活跃(Apache Druid、Apache Hive、Apache Drill、Apache Flink、Apache Phoenix 等项目均在使用)
Apache Calcite 借助开源的 JavaCC 完成 SQL 解析,将 SQL 语句转化为 Java 代码
Apache Calcite 还使用了轻量级 Janino 编译运行时 Java 代码,以便灵活地管理元数据
架构
整体架构
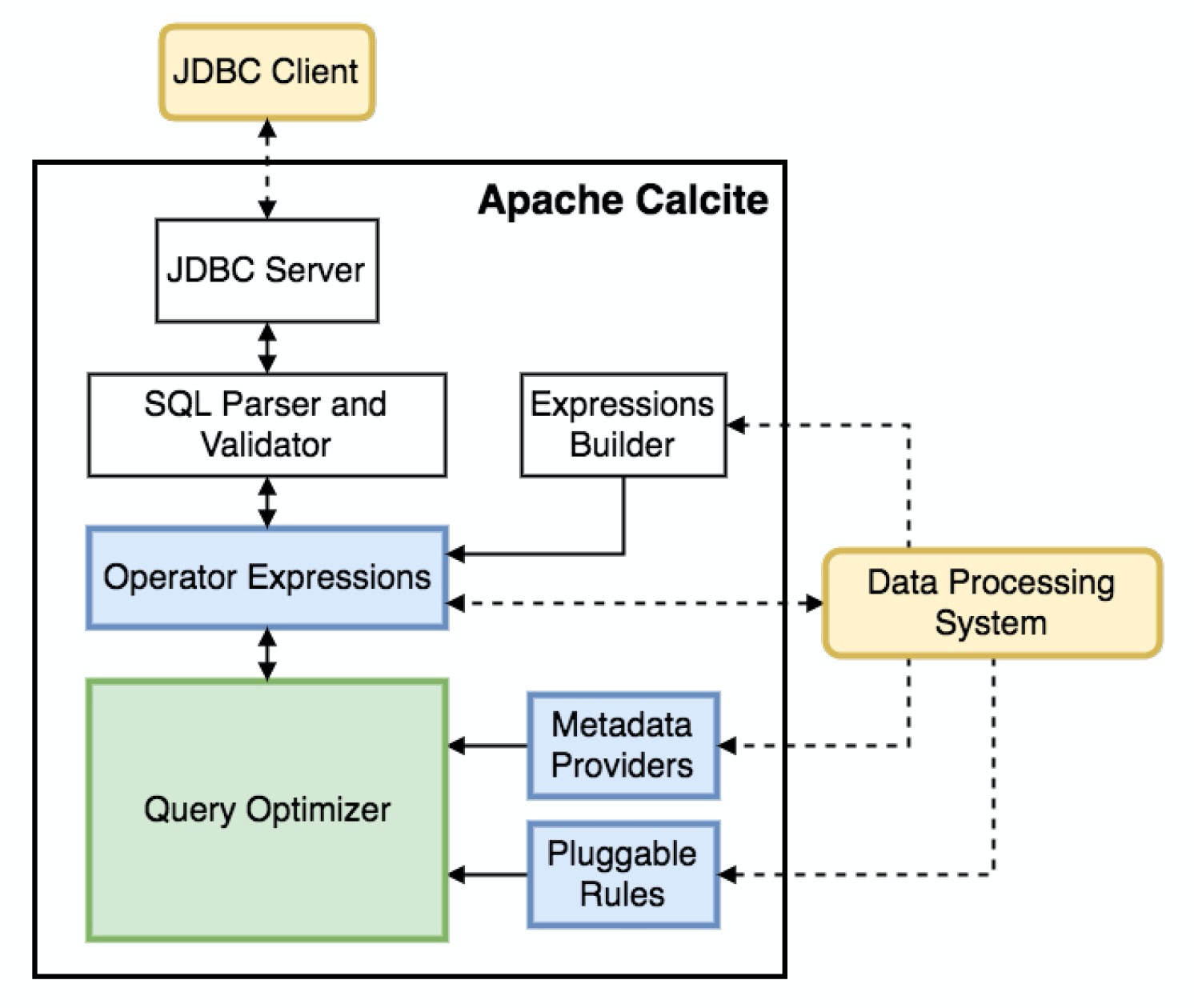
专注的层面
graph TD query_language(fa:fa-language Query Language) query_optimization(fa:fa-fast-forward Query Optimization) query_execution(fa:fa-spinner Query Execution) data_management(fa:fa-cog Data Management) data_storage(fa:fa-database Data Storage) query_language ==> query_optimization query_optimization ==> query_execution query_execution ==> data_management data_management ==> data_storage style data_management fill:#808080 style data_storage fill:#808080
其中,数据管理和存储,交由第三方计算和存储引擎实现
解析流程
graph LR SQL[SQL] Parser(fa:fa-align-left Parser) AST[AST] Validate(fa:fa-check-square-o Validate) RelNode[RelNode] Optimize(fa:fa-fast-forward Optimize) Plan[Plan] Execute(fa:fa-spinner Execute) SQL --> Parser Parser --> AST AST --> Validate Validate --> RelNode RelNode --> Optimize Optimize --> Plan Plan --> Execute style Parser fill:#0099FF style Validate fill:#0099FF style Optimize fill:#0099FF style Execute fill:#0099FF
RBO
谓词下推
graph BT Set1(fa:fa-table Set1) Set2(fa:fa-table Set2) Join(fa:fa-compress Join) Filter(fa:fa-filter Filter) Set1'(fa:fa-table Set1) Set2'(fa:fa-table Set2) Join'(fa:fa-compress Join) Filter'(fa:fa-filter Filter) Set1 --> Join Set2 ==> Join Join ==> Filter Set1' --> Join' Set2' ==> Filter' Filter' ==> Join' style Filter fill:#009933 style Filter' fill:#009933
列裁剪
graph BT Set1(fa:fa-table Set1) Set2(fa:fa-table Set2) Join(fa:fa-compress Join on Set1.id == Set2.id) Res(fa:fa-table Set1.name, Set1.age) Set1'(fa:fa-table Set1) Set2'(fa:fa-table Set2) Crop'(fa:fa-cut Crop and only keep id) Join'(fa:fa-compress Join on Set1.id == Set2.id) Res'(fa:fa-table Set1.name, Set1.age) Set1 --> Join Set2 ==> Join Join ==> Res Set1' --> Join' Set2' ==> Crop' Crop' ==> Join' Join' ==> Res' style Crop' fill:#009933
常量折叠
graph BT Set1(fa:fa-table Set1) Set2(fa:fa-table Set2) Join(fa:fa-compress Join) Res(fa:fa-table Set1.name, Set1.age, 1024 + 996) Set1'(fa:fa-table Set1) Set2'(fa:fa-table Set2) Join'(fa:fa-compress Join) Res'(fa:fa-table Set1.name, Set1.age, 2020) Set1 --> Join Set2 --> Join Join --> Res Set1' --> Join' Set2' --> Join' Join' --> Res' style Res' fill:#009933
比对
| 查询语言 | JDBC | SQL 解析与校验 | Relational Algebra | Execution Engine | |
|---|---|---|---|---|---|
| Apache Drill | SQL | ✔ | ✔ | ✔ | Native |
| Apache Druid | SQL | ✔ | ✔ | ✔ | Native |
| Apache Phoenix | SQL | ✔ | ✔ | ✔ | Apache HBase |
| Apache Solr | SQL | ✔ | ✔ | ✔ | Native, Enumerable, Apache Lucene |
| Apache Storm | SQL | ✔ | ✔ | ✔ | Native |
| Apache Kylin | SQL | ✔ | ✔ | Enumerable, Apache HBase | |
| MapD | SQL | ✔ | ✔ | Native | |
| Lingual | SQL | ✔ | ✔ | Cascading | |
| Apache Hive | SQL | ✔ | Apache Tez, Apache Spark | ||
| Qubole Quark | SQL | ✔ | ✔ | ✔ | Apache Hive, Presto |
| Apache Apex | Streaming SQL | ✔ | ✔ | ✔ | Native |
| Apache Flink | Streaming SQL | ✔ | ✔ | ✔ | Native |
| Apache Samza | Streaming SQL | ✔ | ✔ | ✔ | Native |
实战
下载
1 | $ git clone --depth 1 --single-branch --branch master https://github.com/apache/calcite.git |
编译
1 | $ cd calcite/example/csv |
链接
1 | sqlline> !connect jdbc:calcite:model=src/test/resources/model.json admin admin |
展示所有 Tables
1 | 0: jdbc:calcite:model=src/test/resources/mode> !tables |
1 | +-----------+-------------+------------+--------------+---------+----------+------------+-----------+---------------------------+----------------+ |
查询
1 | 0: jdbc:calcite:model=src/test/resources/mode> SELECT * FROM emps; |
1 | +-------+-------+--------+--------+---------------+-------+------+---------+---------+------------+ |
Join
1 | 0: jdbc:calcite:model=src/test/resources/mode> SELECT d.name, COUNT(*) |
1 | +-----------+--------+ |
内置函数
1 | 0: jdbc:calcite:model=src/test/resources/mode> VALUES CHAR_LENGTH('Hello, ' || 'world!'); |
1 | +--------+ |
社区发展
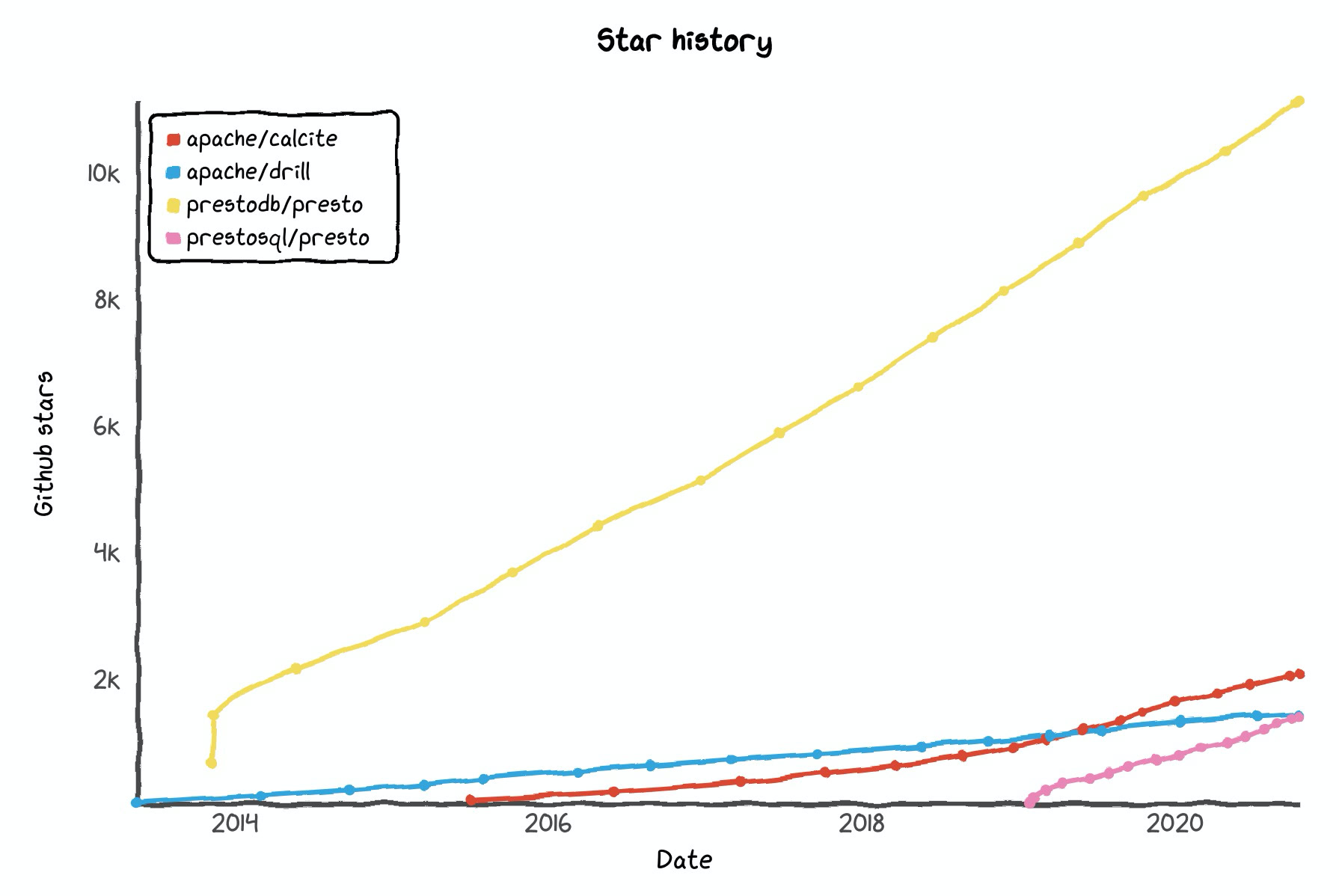
Star 趋势
个人贡献
详见:《如何成为 Apache 的 PMC》
资料
Doc
Paper
- Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources
- The Volcano Optimizer Generator: Extensibility and Efficient Search
- The Cascades Framework for Query Optimization
Github
- JavaCC: The most popular parser generator for use with Java applications
- Janino is a super-small, super-fast Java™ compiler
- Apache Calcite Jira
Blog
Apache Calcite
- Introduction to Apache Calcite
- Apache Calcite 简介
- Apache Calcite 为什么能这么流行
- Apache Calcite 教程 - 关系代数
- 深入浅出 Calcite 与 SQL CBO(Cost-Based Optimizer)优化
JavaCC
欢迎加入我们的技术群,一起交流学习
| 群名称 | 群号 |
|---|---|
| 人工智能(高级) | |
| 人工智能(进阶) | |
| BigData | |
| 算法 |